Pipeline Overview
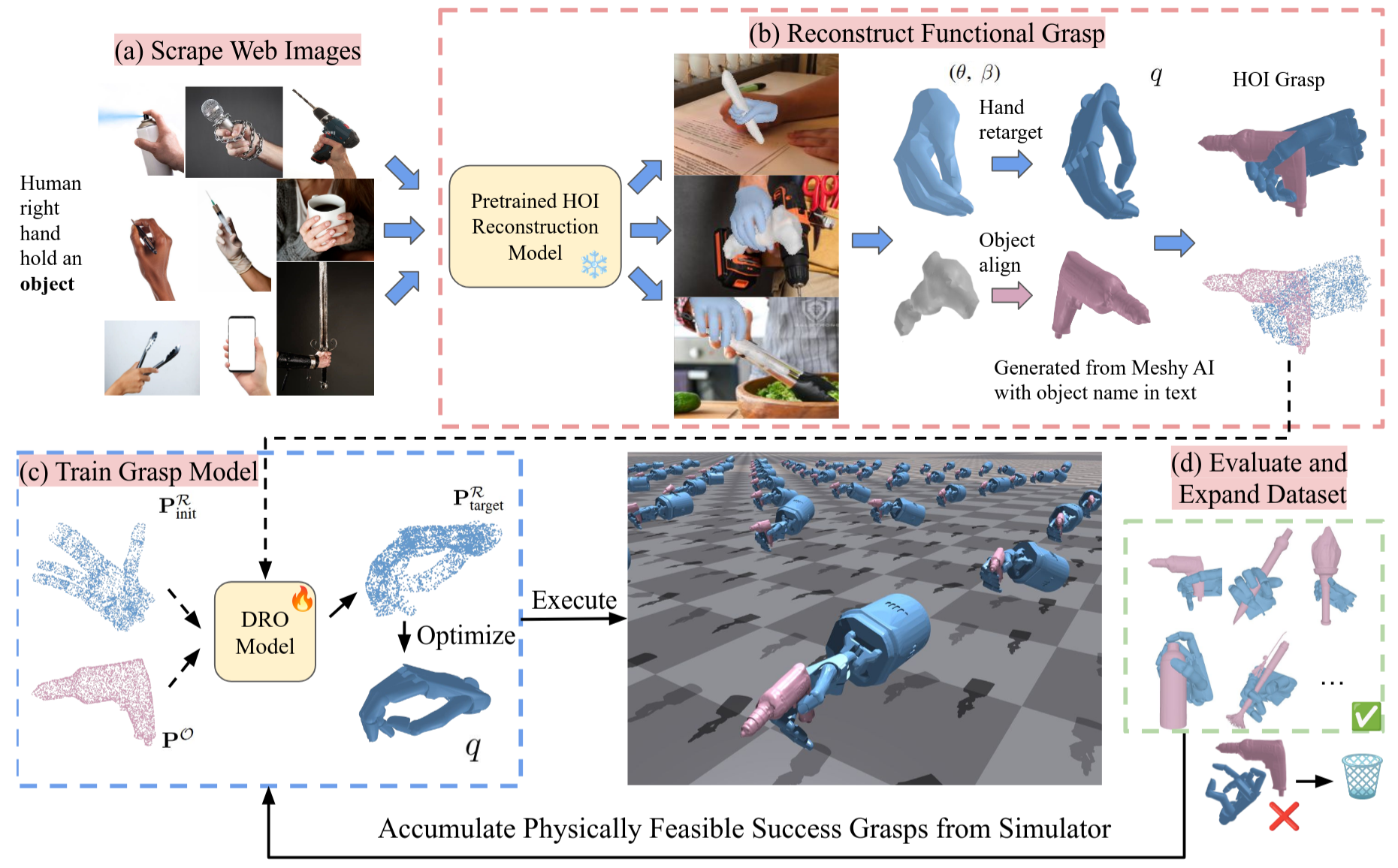
Functional grasping is essential for enabling dexterous multi-finger robot hands to manipulate objects effectively. However, most prior work either focuses on power grasping, which simply involves holding an object still, or relies on costly teleoperated robot demonstrations to teach robots how to grasp each object functionally. Instead, we propose extracting human grasp information from web images since they depict natural and functional object interactions, thereby bypassing the need for curated demonstrations. We reconstruct hand-object interaction (HOI) 3D meshes from RGB images, retarget the human hand to multi-finger robot hands, and align the noisy object mesh with its accurate 3D shape. We show that these relatively low-quality HOI data from inexpensive web sources can effectively train a functional grasping model. To further expand the grasp dataset for seen and unseen objects, we use the initially-trained grasping policy with web data in the IsaacGym simulator to generate physically feasible grasps while preserving functionality. We train the grasping model on 10 object categories and evaluate it on 9 unseen objects, including challenging items such as syringes, pens, spray bottles, and tongs, which are underrepresented in existing datasets. We train the model on the web HOI dataset, achieving a 75.8% success rate on seen objects and 61.8% across all objects in simulation, with a 6.7% improvement in success rate and a 1.8$\times$ increase in functionality ratings over baselines. Simulator-augmented data further boosts performance from 61.8% to 83.4%. The sim-to-real transfer to the LEAP Hand achieves a 85% success rate.
Grasp 0
Grasp 1
Grasp 2
Web2Grasp
All videos are sped up by 2.25 times

Wine Glass

Tong

Phone

Power Drill

Mug

Microphone

Spray

Syringe